Introduction
There’s been a lot of buzz lately about Generative AI, LLMs and their applications. It’s becoming increasingly clear that machine learning techniques are augmenting the world of software development and security research. One such example is the LangChain framework, which provides a powerful toolkit for developing applications powered by language models. This framework can enable developers to gain deep insights into their codebase, identify potential bugs or vulnerabilities (this is the part we’re interested in 😉), and improve the overall quality and efficiency of their software. In this blog post, we’ll explore the LangChain framework and how it can be used to streamline the vulnerability research process.
LangChain? 🦜🔗
A quick overview of LangChain and some of its capabilities for anyone who is unfamiliar. Everything LangChain can do is outside the scope of this blog post, I encourage you to research and let your imagination run wild.
LLMs in isolation are usually not powerful enough to create a full featured application, they normally take a string as input and output a string (known as a “completion”). This is where LangChain can help. What this looks like in practice is that LangChain is the orchestrator, making it trivial to chain LLMs together. It can use the output of one as context for the next LLM, and even provides “agents” for tasks that LLMs cannot handle (like google searching)!
Examples
Two quick code snippets to help break this down. First up, a text embedding example. Text embedding models take text input and return a list of floats (embeddings), which are the numerical representation of the input text. Embeddings help extract information from text, which can then be used later; for example, for calculating similarities between texts. Math! 🎉
# pip install openai tiktoken
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# The embeddings model takes a text as an input and outputs a list of floats
text = "Alice has a parrot. What animal is Alice's pet?"
text_embedding = embeddings.embed_query(text)
More on why this matters in a bit.
Lastly, an agent example. Specifically, an agent is a stateless wrapper around a prompt chain which takes care of formatting tools into the prompt, as well as parsing the responses obtained from the chat model. It takes in user input and returns a response corresponding to an “action” to take and a corresponding “action input”.
Here is some code in which our agent first looks up the date of Joe Biden’s birth using Wikipedia and then calculates how old he was when we hit the year 2000. I specifically phrased my prompt on the last line to not include the “year 2000” to see how well the model understands.
import os
# pip install --upgrade langchain openai wikipedia
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
if OPENAI_API_KEY is None:
print("missing api key")
exit(-1)
# First, let's load the language model we're going to use to control the agent.
llm = OpenAI(temperature=0)
tools = load_tools(["wikipedia", "llm-math"], llm=llm)
agent = initialize_agent(tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True)
agent.run("When was Joe Biden born? How old was he at the turn of the current millennium?")

As we can see, our application made a chain of decisions without any human intervention:
- I need to find out how old Joe Biden is.
- I was given the
wikipediatool. Search for Joe Biden using wikipedia. - Given Joe Biden’s birthdate, use the
llm-mathtool to calculate his age on Jan 1st, 2000. - Output result.
Pretty cool right?
LangChain and Offensive Security Research (So What?) 🤔
So what? Well, given the examples above of how text embeddings can be used to calculate similarties between text (source code is text 😉) and additionally how LangChain allows us to trivially string together a variety of tasks, I’m sure you can think of a few ways this may apply to Offensive Security research. Armed with information that can be derived from text embeddings and a powerful enough model, LangChain can automatically identify programming languages and libraries used in a codebase, as well as extract key information such as variable names and function calls. It can also identify common patterns and anomalies in the code, making it easier to detect potential bugs or vulnerabilities. Let’s see a demo ❗
Demo 👨🏾💻
Let’s put all the pieces together! Here’s the script I’m using, don’t worry I’ll explain 🙂
import os
# pip install --upgrade langchain deeplake openai tiktoken
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import DeepLake
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from deeplake.core.dataset import Dataset
# Cant continue w/o API key
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
if OPENAI_API_KEY is None:
print("missing api key")
exit(-1)
# We'll be using OpenAI's embeddings
EMBEDDINGS = OpenAIEmbeddings(disallowed_special=())
TARGET_REPO = './Damn-Vulnerable-Bank'
def load_repo_files() -> Dataset:
"""
Walk our target codebase and load all our files
for chunking and then text embedding
"""
root_dir = TARGET_REPO
documents = []
for dirpath, dirnames, filenames in os.walk(root_dir):
for file in filenames:
try:
loader = TextLoader(os.path.join(dirpath, file), encoding='utf-8')
documents.extend(loader.load_and_split())
except Exception as e:
print(e)
# chunk our files
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
chunks = text_splitter.split_documents(documents)
# generate text embeddings for our target codebase
# store in local database ./deeplake/
db = DeepLake(embedding_function=EMBEDDINGS)
db.add_documents(chunks)
return db
def construct_chain() -> ConversationalRetrievalChain:
"""
Build a retriever for our dataset, then build and return a
ConversationalChain that we can interact with
"""
db = load_repo_files()
retriever = db.as_retriever()
retriever.search_kwargs['distance_metric'] = 'cos'
retriever.search_kwargs['fetch_k'] = 100
retriever.search_kwargs['maximal_marginal_relevance'] = True
retriever.search_kwargs['k'] = 10
model = ChatOpenAI(model='gpt-3.5-turbo')
qa = ConversationalRetrievalChain.from_llm(model,retriever=retriever)
return qa
def main():
chat_history = []
questions = [
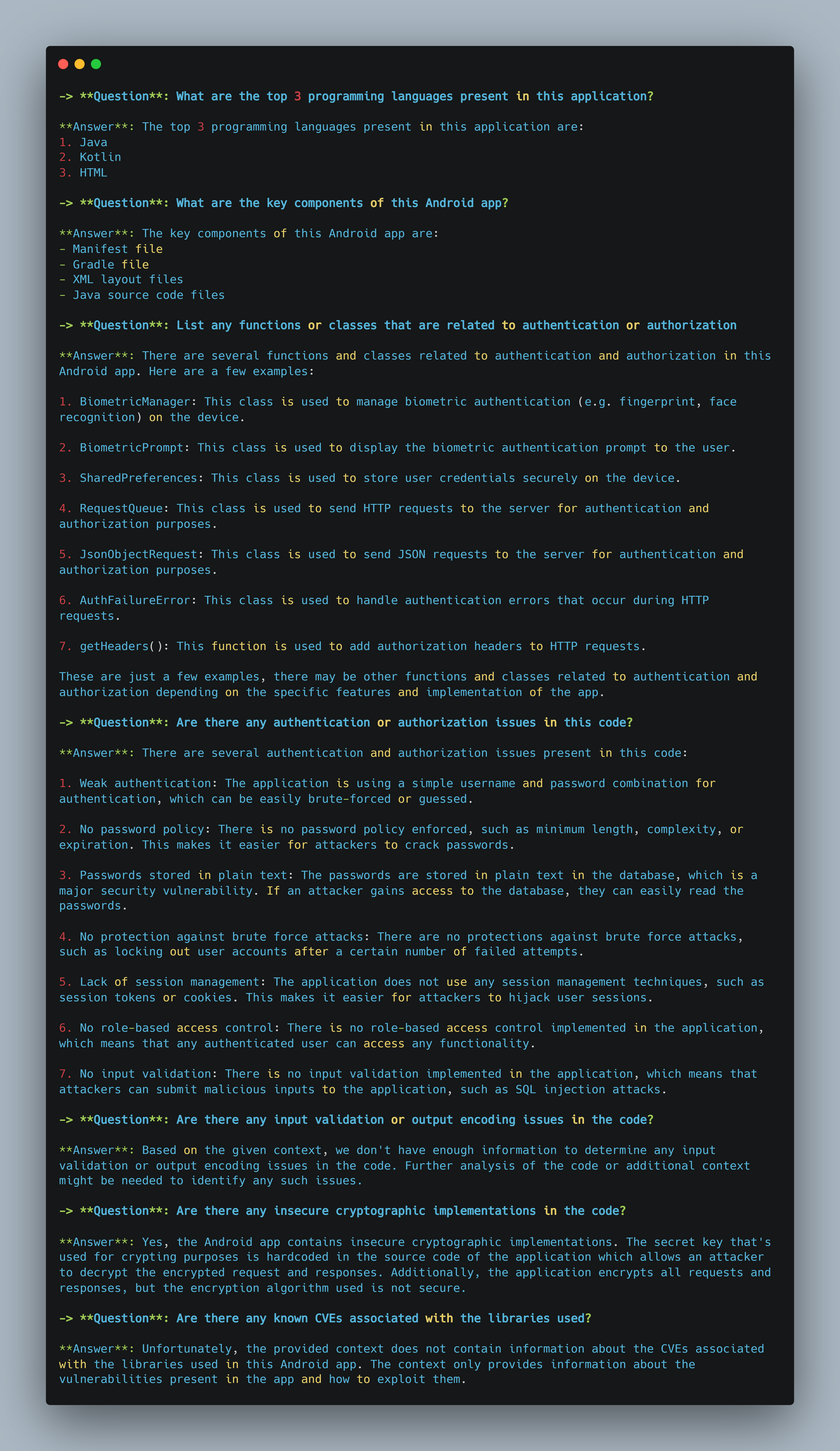
"What are the top 3 programming languages present in this application?",
"What are the key components of this Android app?",
"List any functions or classes that are related to authentication or authorization",
"Are there any authentication or authorization issues in this code?",
"Are there any input validation or output encoding issues in the code?",
"Are there any insecure cryptographic implementations in the code?",
"Are there any known CVEs associated with the libraries used?",
]
qa_chain = construct_chain()
for question in questions:
result = qa_chain({"question": question, "chat_history": chat_history})
chat_history.append((question, result['answer']))
print(f"-> **Question**: {question} \n")
print(f"**Answer**: {result['answer']} \n")
main()
Everything up until def load_repo_files is all environment setup. The target repo was downloaded locally.
Diving into the load_repo_files function:
- We iterate over our repository, grabbing the full path for each filename and loading them into a list.
- Then we split the text of each of our files into chunk sizes of 1000 for easier embedding
- Finally we generate our text embeddings, store them locally in our
DeepLakedatabase and return it
The construct_chain isnt as daunting as it looks either:
- Get a handle to our embeddings database
- Construct a
Retrieverwhich is just a way for us to structure our data in a way that can be queried by a LLM - Select which Model we want to use to query our text embeddings for relevant information. We’re going w/ gpt-3.5. I dont have gpt-4 access yet 😭
- Return our
ConversationalRetrievalChainthat we will interact with
Finally, our main function driver simply asks questions we want answered about our codebase and returns the answers we get back from our LLM.
Results ❓❓
Okay that’s a lot of text, is this worth a damn? Let’s see some results.
As we can see my list of questions about our target codebase, Damn-Vulnerable-Bank, is the following:
- What are the top 3 programming languages present in this application?
- What are the key components of this Android app?
- List any functions or classes that are related to authentication or authorization
- Are there any authentication or authorization issues in this code?
- Are there any input validation or output encoding issues in the code?
- Are there any insecure cryptographic implementations in the code?
- Are there any known CVEs associated with the libraries used?
Here’s what our Model was able to tell us in a matter of seconds
Conclusion/Future Research 🧠
Not too bad in my opinion! The limitations of this PoC are probably based a few different things, namely my prompt engineering skills and the model I chose to use. I’m assuming a more powerful model like gpt-4 or one tuned for code analysis may produce even stronger results!
I’m still learning about all this, just a few months ago I was enthralled by ChatGPT so I figured the best way to demystify is to dive head first into experimenting. The LangChain framework offers a powerful toolkit for making the most of NLP and machine learning algorithms; the sky is the limit especially when you consider how Agents can work together.
Always open to learning more and discussing how others are using LangChain. Some ideas that come to mind:
Auto stand up red team/phishing infrastructure
Automating an entire phishing campaign
- Send emails, gather responses, sentiment analysis, generate more convincing emails based sentiment, etc
Speeding up the vulnerability research process
References
- https://platform.openai.com/docs/introduction/overview
- https://python.langchain.com/en/latest/getting_started/getting_started.html
- https://www.einblick.ai/blog/what-is-langchain-why-use-it/
- https://github.com/Tor101/LangChain-CheatSheet